SAP HANA Architecture & Overview
Qs. What is SAP HANA?
SAP HANA is an in-memory database.
It is a combination of hardware and software made to process massive real time data using In-Memory computing.
It combines row-based, column-based database technology.
It’s best suited for performing real-time analytics, and developing and deploying real-time applications.
An in-memory database means all the data is stored in the memory (RAM). This is no time wasted in loading the data from hard-disk to RAM or while processing keeping some data in RAM and temporary some data on disk. Everything is in-memory all the time, which gives the CPUs quick access to data for processing.
SAP HANA is equipped with multiengine query processing environment which supports relational as well as graphical and text data within same system. It provides features that support significant processing speed, handle huge data sizes and text mining capabilities.
Qs. So is SAP making/selling the software or the hardware?
SAP has partnered with leading hardware vendors (HP, Fujitsu, IBM, Dell etc) to sell SAP certified hardware for HANA.
SAP is selling licenses and related services for the SAP HANA product which includes the SAP HANA database, SAP HANA Studio and other software to load data in the database.
Qs. What is the language SAP HANA is developed in?
The SAP HANA database is developed in C++.
Qs. What is the operating system supported by HANA?
Currently SUSE Linux Enterprise Server x86-64 (SLES) 11 SP1 is the Operating System supported by SAP HANA.
Qs. Can I just increase the memory of my traditional Oracle database to 2TB and get similar performance?
You might have performance gains due to more memory available for your current Oracle/Microsoft/Teradata database but HANA is not just a database with bigger RAM.
It is a combination of a lot of hardware and software technologies. The way data is stored and processed by the In-Memory Computing Engine (IMCE) is the true differentiator. Having that data available in RAM is just the icing on the cake.
Qs. What are the row-based and column based approach?
Row based tables:
It is the traditional Relational Database approach
It store a table in a sequence of rows
Column based tables:
It store a table in a sequence of columns i.e. the entries of a column is stored in contiguous memory locations.
SAP HANA is particularly optimized for column-order storage.
SAP HANA supports both row-based and column-based approach.
Qs. What are the advantages and disadvantages of row-based tables?
Row based tables have advantages in the following circumstances:
The application needs to only process a single record at one time (many selects and/or updates of single records).
The application typically needs to access a complete record (or row).
Neither aggregations nor fast searching are required.
The table has a small number of rows (e. g. configuration tables, system tables).
Row based tables have advantages in the following circumstances:
In case of analytic applications where aggregation are used and fast search and processing is required. In row based tables all data in a row has to be read even though the requirement may be to access data from a few columns.
Qs. What are the advantages of column-based tables?
Advantages:
o Faster Data Access:
Only affected columns have to be read during the selection process of a query. Any of the columns can serve as an index.
o Better Compression:
Columnar data storage allows highly efficient compression because the majority of the columns contain only few distinct values (compared to number of rows).
o Better parallel Processing
In a column store, data is already vertically partitioned. This means that operations on different columns can easily be processed in parallel. If multiple columns need to be searched or aggregated, each of these operations can be assigned to a different processor core
Qs. In HANA which type of tables should be preferred – Row-based or Column-based?
SQL queries involving aggregation functions take a lot of time on huge amounts of data because every single row is touched to collect the data for the query response.
In columnar tables, this information is stored physically next to each other, significantly increasing the speed of certain data queries. Data is also compressed, enabling shorter loading times.
Conclusion:
To enable fast on-the-fly aggregations, ad-hoc reporting, and to benefit from compression mechanisms it is recommended that transaction data is stored in a column-based table.
The SAP HANA data-base allows joining row-based tables with column-based tables. However, it is more efficient to join tables that are located in the same row or column store. For example, master data that is frequently joined with transaction data should also be stored in column-based tables.
Qs. Why materialized aggregates are not required in HANA?
Since the SAP HANA database resides entirely in-memory all the time, additional complex calculations, functions and data-intensive operations can happen on the data directly in the database. Hence materialized aggregations are not required.
It also provides benefits like
Simplified data model
Simplified application logic
Higher level of concurrency
Qs. How does SAP HANA support Massively Parallel Processing?
With availability of Multi-Core CPUs, higher CPU execution speeds can be achieved. HANA Column-based storage makes it easy to execute operations in parallel using multiple processor cores. In a column store data is already vertically partitioned. This means that operations on different columns can easily be processed in parallel. If multiple columns need to be searched or aggregated, each of these operations can be assigned to a different processor core. In addition operations on one column can be parallelized by partitioning the column into multiple sections that can be processed by different processor cores. With the SAP HANA database, queries can be executed rapidly and in parallel.
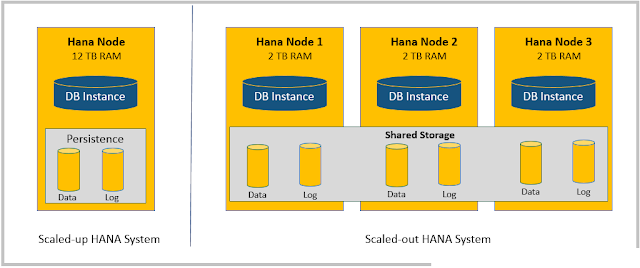
Qs. Describe SAP HANA Database Architecture in brief.
The SAP HANA database is developed in C++ and runs on SUSE Linux Enterpise Server. SAP HANA database consists of multiple servers and the most important component is the Index Server. SAP HANA database consists of Index Server, Name Server, Statistics Server, Preprocessor Server and XS Engine.
Index Server:
Index server is the main SAP HANA database component
It contains the actual data stores and the engines for processing the data.
The index server processes incoming SQL or MDX statements in the context of authenticated sessions and transactions.
Persistence Layer:
The database persistence layer is responsible for durability and atomicity of transactions. It ensures that the database can be restored to the most recent committed state after a restart and that transactions are either completely executed or completely undone.
Preprocessor Server:
The index server uses the preprocessor server for analyzing text data and extracting the information on which the text search capabilities are based.
Name Server:
The name server owns the information about the topology of SAP HANA system. In a distributed system, the name server knows where the components are running and which data is located on which server.
Statistic Server:
The statistics server collects information about status, performance and resource consumption from the other servers in the system.. The statistics server also provides a history of measurement data for further analysis.
Session and Transaction Manager:
The Transaction manager coordinates database transactions, and keeps track of running and closed transactions. When a transaction is committed or rolled back, the transaction manager informs the involved storage engines about this event so they can execute necessary actions.
XS Engine:
XS Engine is an optional component. Using XS Engine clients can connect to SAP HANA database to fetch data via HTTP.
Qs.What is ad hoc analysis??
In traditional data warehouses, such as SAP BW, a lot of pre-aggregation is done for quick results. That is the administrator (IT department) decides which information might be needed for analysis and prepares the result for the end users. This results in fast performance but the end user does not have flexibility.
The performance reduces dramatically if the user wants to do analysis on some data that is not already pre-aggregated. With SAP HANA and its speedy engine, no pre-aggregation is required. The user can perform any kind of operations in their reports and does not have to wait hours to get the data ready for analysis.
Qs. What is the maximum number of tables in a schema?
131072
Qs. What can be the maximum table name length?
127 characters
Qs. What can be the maximum column name length?
127 characters
Qs. What can be the maximum number of columns in a table?
1000
Qs. What can be the maximum number of columns in a view?
1000
Qs. What can be the maximum number of partitions of a column table?
1000
Qs. What can be the maximum number of rows in each table?
Limited by storage size RS: 1TB/sizeof(row)
CS: 2^31 * number of partitions
Qs. In which table you can get the current system limits?
M_SYSTEM_LIMITS
SAP HANA Interview Questions and Answers
SLT Replication
Qs. What are the different types of replication techniques?
There are 3 types of replication techniques:
SAP Landscape Transformation (SLT)
SAP Business Objects Data Services (BODS)
SAP HANA Direct Extractor Connection (DXC)
Note: There is one more replication technique called Sybase replication. It was part of initial offering for HANA replication, but not positioned / supported anymore due to licensing issues and complexity and mostly because SLT provides the same features.
Qs. What is SLT?
The SAP Landscape Transformation (LT) Replication Server is the SAP technology that allows us to load and replicate data in real-time from SAP source systems and non-SAP source systems to an SAP HANA environment.
The SAP LT Replication Server uses a trigger-based replication approach to pass data from the source system to the target system.
Qs. What is the advantage of SLT replication?
Advantages:
SAP LT uses trigger based approach. Trigger-based approach has no measureable performance impact in source system.
It provides transformation and filtering capability.
It allows real-time (and scheduled) data replication, replicating only relevant data into HANA from SAP and non-SAP source systems.
It is fully integrated with HANA Studio.
Replication from multiple source systems to one HANA system is allowed, also from one source system to multiple HANA systems.
Qs. Is it possible to use a replication for multiple sources and target SAP HANA systems?
Yes, the SAP LT Replication Server supports both 1:N replication and and N:1 replication.
o Multiple source system can be connected to one SAP HANA system.
o One source system can be connected to multiple SAP HANA systems. Limited to 1:4 only.
Qs. Is there any pre-requisite before creating the configuration and replication?
For SAP source systems:
DMIS add-on must be installed in SLT replication server.
An RFC connection between the SAP source system and the SAP LT Replication Server has to be established.
User for RFC connection must have the role IUUC_REPL_REMOTE assigned.
Do not use a DDIC user for RFC connection.
For non-SAP source systems:
DMIS add-on is not required.
A database user has to be created with appropriate authorizations in advance and establish the database connection by using transaction DBCO in the SAP LT Replication Server.
Ensure the database-specific library components for the SAP 7.20 REL or EXT kernel are installed in the SAP LT Replication Server.
Qs. What is Configuration and Monitoring Dashboard?
It is an application that runs on SLT replication server to specify configuration information (such as source system, target system, and relevant connections) so that data can be replicated.
It can also use it to monitor the replication status (transaction LTR).
Status Yellow: It may occur due to triggers which are not yet created successfully.
Status Red: It may occur if master job is aborted (manually in transaction SM37).
Qs. What is advanced replication settings (transaction IUUC_REPL_CONT)?
The Advanced Settings (transaction IUUC_REPL_CONT) allows you to define and change various table settings for a configuration such as:
Partitioning and structure changes for target tables in HANA
Table-specific transformation and filter rules
Adjusting the number of jobs (and reading type) to accelerate the load/replication process
Qs. What is Latency?
It is the length of time to replicate data (a table entry) from the source system to the target system.
Qs. What is logging table?
A table in the source system that records any changes to a table that is being replicated. This ensures that SLT replication server can replicate these changes to the target system.
Qs. What are Transformation rules?
A rule specified in the Advanced Replication settings transaction for source tables such that data is transformed during the replication process. Example you can specify rule to Convert fields
Fill empty fields
Skip records
Qs. What happens when you set-up a new configuration?
When a new configuration in the SAP LT Replication Server is created, the database connection is automatically created along with a schema GUID and Mass transfer id (MT_ID).
A schema GUID ensures that configurations with the same schema name can be created.
The Mass transfer ID is used in the naming of SLT jobs and the system can uniquely identify a schema.
The mapping of mass transfer IDs and related schema are stored in the SLT control table DMC_MT_HEADER in the SAP LT Replication Server.
Qs. What are the jobs involved in replication process?
Following jobs are involved in replication process:
Master Job (IUUC_MONITOR_)
Master Controlling Job (IUUC_REPLIC_CNTR_)
Data Load Job (DTL_MT_DATA_LOAD__)
Migration Object Definition Job (IUUC_DEF_MIG_OBJ_)
Access Plan Calculation Job (ACC_PLAN_CALC__)
Qs. What is the purpose of master job (IUUC_MONITOR_)?
Every 5 seconds, the monitoring job checks in the SAP HANA system whether there are new tasks and, if so, triggers the master control jobs. It also deletes the processed entries (tasks) from table RS_ORDER and writes statistics entries into table RS_STATUS (in the relevant schema in the SAP HANA system).
Qs. What is the purpose of master controller job (IUUC_REPLIC_CNTR_)?
This job is scheduled on demand and is responsible for:
Creating database triggers and logging table in the source system
Creating synonyms
Writing new entries in admin tables in SLT server when a new table is loaded/replicated
Qs. What is the purpose of Data Load Job (DTL_MT_DATA_LOAD__)?
This job should always be active. If the job does not complete successfully, the master controller job restarts it.
This job is responsible for:
Loading data (load)
Replicating data (replication)
Changing status flag for entries in control tables in the SAP LT Replication Server
Qs. What is the purpose of Migration Object Definition Job (IUUC_DEF_MIG_OBJ_)?
This job defines the migration object of a specific table (that you choose to load/replicate), which is the fundamental object for LT replication. The migration object definition should normally be quite fast for all tables.
Qs. What is the purpose of Access Plan Calculation Job (ACC_PLAN_CALC__)?
This job calculates the access plan of a specific table (that you choose to load/replicate), and the access plan is used for data load or replication. The access plan is also a fundamental object for the replication. For a normal sized table, access plan calculation should finish quite quickly (less than 1 minute) while large tables might take up to several hours to finish.
Qs. What is the relation between the number of data transfer jobs in the configuration settings and the available BGD work processes?
Each job occupies 1 BGD work processes in SLT replication server. For each configuration, the parameter Data Transfer Jobs restricts the maximum number of data load job for each mass transfer ID (MT_ID).
A mass transfer ID requires at least 4 background jobs to be available:
One master job
One master controller job
At least one data load job
One additional job either for migration/access plan calculation/to change configuration settings in “Configuration and Monitoring Dashboard”.
Qs. If you set the parameter “data transfer jobs” to 04 in a configuration “SCHEMA1”, a mass transfer ID 001 is assigned. Then what jobs should be in the system?
1 Master job (IUUC_MONITOR_SCHEMA1)
1 Master Controller job (IUUC_REPL_CNTR_001_0001)
At most 4 parallel jobs for MT_ID 001 (DTL_MT_DATA_LOAD_001_ 01/~02/~03/~04)
Qs. What happens after the SLT replication is over?
The SLT replication server creates 1 user, 4 roles, 2 stored procedures and 8 tables.
1 User
1 Privilege
4 Roles
_DATA_PROV
_POWER_USER
_USER_ADMIN
_SELECT
2 Stored procedures
RS_GRANT_ACCESS
RS_REVOKE_ACCESS
8 Tables
DD02L
DD02T|
RS_LOG_FILES
RS_MESSAGES
RS_ORDER
RS_ORDER_EXT
RS_SCHEMA_MAP
RS_STATUS
Qs. What are the different replication scenarios?
Different replication scenarios are:
Load, Replicate, Stop, Suspend and Resume.
Load:
Starts an initial load of replication data from the source system. The procedure is a one-time event. After it is completed, further changes to the source system database will not be replicated.
For the initial load procedure, neither database triggers nor logging tables are created in the source system. Default settings use reading type 3 (DB_SETGET) with up to 3 background jobs in parallel to load tables in parallel or subsequently into the HANA system.
Replicate:
Combines an initial load procedure and the subsequent replication procedure (real time or scheduled).
Before the initial load procedure will start, database trigger and related logging table are created for each table in the source system as well as in SLT replication server.
Stop:
Stops any current load or replication process of a table.
The stop function will remove the database trigger and related logging tables completely. Only use this function if you do want to continue a selected table otherwise you must initially load the table again to ensure data consistency.
Suspend:
Pauses a table from a running replication. The database trigger will not be deleted from the source system. The recording of changes will continue and related information is stored in the related logging tables in the source system.
If you suspend tables for a long time the size of logging tables may increase and adjust the table space if required.
Resume:
Restarts the application for a suspended table. The previous suspended replication will be resumed (no new initial load required).
Qs. What happens if the replication is suspended for a long period of time or system outage of SLT or HANA system?
The size of the logging tables increases.
Qs. How to avoid unnecessary logging information from being stored?
Pause the replication by stopping the schema-related jobs.
Qs. Will the table size in SAP HANA database and in the source system the same?
No. As HANA database supports compression, the table size in SAP HANA may be decreased.
Qs. When to go for table partitioning?
If the table size in HANA database exceeds 2 billion records, split the table by using portioning features by using “Advanced replication settings” (transaction IUUC_REPL_CONT, tab page IUUC_REPL_TABSTG).
Qs. Where do you define transformation rules?
By using “Advanced replication settings” (transaction IUUC_REPL_CONT, tab page IUUC ASS RULE MAP)
Qs. Are there any special considerations if the source system is non-SAP system?
The concept of trigger-based replication is actually meant for SAP source systems. The main differences are:
There will be a database connection between non-SAP source and SLT system instead of RFC.
Source must have primary key
Tables DD02L, DD02T which contains metadata are just initially loaded but not replicated.
The read modules reside on SLT system.
Tables with database specific formats may need transformation rules before they are replicated.
Only SAP supported databases are supported as non-SAP source systems.
Qs. Does SLT for SAP HANA support data compression like SAP HANA database?
Yes, this is automatically covered by the RFC connection used for data replication from the SAP source system.
Qs.What factors influence the change/increase the number of jobs?
Number of configurations managed by the SLT replication server Number of tables to be loaded/replicated for each configuration Expected speed of initial load Expected replication latency time. As a rule of thumb, one BDG job should be used for each 10 tables in replication to achieve acceptable latency times.
Qs.When to change the number of Data Transfer jobs?
If the speed of the initial load/replication latency time is not satisfactory If SLT replication server has more resources than initially available, we can increase the number of data transfer and/or initial load jobs After the completion of the initial load, we may want to reduce the number of initial load jobs
Qs.What are the jobs involved in replication process?
1. Master Job (IUUC_MONITOR_)
2. Master Controlling Job (IUUC_REPLIC_CNTR_)
3. Data Load Job (DTL_MT_DATA_LOAD__)
4.Migration Object Definition Job (IUUC_DEF_MIG_OBJ_)
5.Access Plan Calculation Job (ACC_PLAN_CALC__)
Qs.What is the relation between the number of data transfer jobs in the configuration settings and the available BGD work processes?
Each job occupies 1 BGD work processes in SLT replication server. For each configuration, the parameter Data Transfer Jobs restricts the maximum number of data load job for each mass transfer ID (MT_ID).
A mass transfer ID requires at least 4 background jobs to be available: One master job One master controller job At least one data load job One additional job either for migration/access plan calculation/to change configuration settings in “Configuration and Monitoring Dashboard”.
Qs.If you set the parameter “data transfer jobs” to 04 in a configuration “SCHEMA1”, a mass transfer ID 001 is assigned. Then what jobs should be in the system?
1 Master job (IUUC_MONITOR_SCHEMA1) 1 Master Controller job (IUUC_REPL_CNTR_001_0001) At most 4 parallel jobs for MT_ID 001 (DTL_MT_DATA_LOAD_001_ 01/~02/~03/~04)
Performance: If lots of tables are selected for load / replication at the same time, it may happen that there are not enough background jobs available to start the load procedure for all tables immediately. In this case you can increase the number of initial load jobs, otherwise tables will be handled sequentially.
For tables with large volume of data, you can use the transaction “Advanced Replication Settings (IUUC_REPL_CONT)” to further optimize the load and replication procedure for dedicated tables.
Qs.What happens after the SLT replication is over?
The SLT replication server creates 1 user, 4 roles, 2 stored procedures and 8 tables. 1 User 1 Privilege 4 Roles _DATA_PROV _POWER_USER _USER_ADMIN _SELECT 2 Stored procedures RS_GRANT_ACCESS, RS_REVOKE_ACCESS 8 Tables DD02L, DD02T, RS_LOG_FILES, RS_MESSAGES, RS_ORDER, RS_ORDER_EXT, RS_SCHEMA_MAP, RS_STATUS
Qs.What are the different replication scenarios?
Load, Replicate, Stop, Suspend and Resume.
Before you select any application table, the initial load of the tables DD02L, DD02T & DD08L must be completed as they contain the metadata information.
Load: Starts an initial load of replication data from the source system. The procedure is a one-time event. After it is completed, further changes to the source system database will not be replicated.
For the initial load procedure, neither database triggers nor logging tables are created in the source system. Default settings use reading type 3 (DB_SETGET) with up to 3 background jobs in parallel to load tables in parallel or subsequently into the HANA system.
Replicate: Combines an initial load procedure and the subsequent replication procedure (real time or scheduled).
Before the initial load procedure will start, database trigger and related logging table are created for each table in the source system as well as in SLT replication server.
Stop Replication: Stops any current load or replication process of a table.
The stop function will remove the database trigger and related logging tables completely. Only use this function if you do want to continue a selected table otherwise you must initially load the table again to ensure data consistency.
Suspend: Pauses a table from a running replication. The database trigger will not be deleted from the source system. The recording of changes will continue and related information is stored in the related logging tables in the source system.
If you suspend tables for a long time the size of logging tables may increase and adjust the table space if required.
Resume: Restarts the application for a suspended table. The previous suspended replication will be resumed (no new initial load required).
Qs.What happens if the replication is suspended for a long period of time or system outage of SLT or HANA system?
The size of the logging tables increases.
Qs.How to avoid unnecessary logging information from being stored?
Pause the replication by stopping the schema-related jobs.
Qs.Will the table size in SAP HANA database and in the source system the same?
No as HANA database supports compression.
Qs.When to go for table partitioning?
If the table size in HANA database exceeds 2 billion records, split the table by using portioning features by using “Advanced replication settings” (transaction IUUC_REPL_CONT, tab page IUUC_REPL_TABSTG).
Qs.Where do you define transformation rules?
By using “Advanced replication settings” (transaction IUUC_REPL_CONT, tab page IUUC ASS RULE MAP)
Qs.Are there any special considerations if the source system is non-SAP system?
The concept of trigger-based replication is actually meant for SAP source systems. The main differences are: There will be a database connection between non-SAP source and SLT system instead of RFC. Source must have primary key Tables DD02L, DD02T which contains metadata are just initially loaded but not replicated. The read modules reside on SLT system. Tables with database specific formats may need transformation rules before they are replicated. Only SAP supported databases (with respective DBSL for SAP Net Weaver 7.02) are supported as non-SAP source systems.
Qs.What are the potential issues in the creation of configuration?
Missing add-on DMIS_2010 in source system Missing the proper role of SAP_IUUC_REPL_REMOTE for RFC user ( SAP_IUUC_USER for SLT system ) Logon credentials are not correct
Qs.How can you ensure that data is consistent in source system and HANA system?
Since any changes in the source system is tracked in dedicated logging tables, the replication status for each changed data record is transparent. A entry of logging table is deleted after a successful commit statement from HANA database and this procedure ensures the data consistency between source system and HANA system.
Qs.Does SLT for SAP HANA support data compression like SAP HANA database?
Yes, this is automatically covered by the RFC connection used for data replication from the SAP source system.
SAP Landscape Transformation
1.What are the different types of replication techniques?
1.ETL based replication using BODS
2.Trigger based replication using SLT
3.Extractor based data acquisition using DXC
2.What is SLT?
SLT stands for SAP Landscape Transformation which is a trigger based replication. SLT replication server is the replication technology to pass data from source system to the target system. The source can be either SAP or non-SAP. Target system is SAP HANA system which contains HANA database.
3.Is it possible to load and replicate data from one source system to multiple target database schemas of HANA system?
Yes. It is possible for up to 4.
4.Is it possible to specify the type of data load and replication?
Yes either in real time, or scheduled by time or by interval.
5.What is Configuration in SLT?
The information to create the connection between the source system, SLT system, and the SAP HANA system is specified within the SLT system as a Configuration. You can define a new configuration in Configuration & Monitoring Dashboard (transaction LTR).
6.Is there any pre-requisite before creating the configuration and replication?
For the SAP source systems DMIS add-on is installed in SLT replication server. User for RFC connection has the role IUUC_REPL_REMOTE assigned but not DDIC. For non-SAP source systems DMIS add-on is not required and grant a database user sufficient authorization for data replication.
7.What is Configuration and Monitoring Dashboard?
It is an application that runs on SLT replication server to specify configuration information (such as source system, target system, and relevant connections) so that data can be replicated. It can also use it to monitor the replication status (transaction LTR). Status Yellow: It may occur due to triggers which are not yet created successfully. Status Red: It may occur if master job is aborted (manually in transaction SM37).
8.What is advanced replication settings?
A transaction that runs on SLT replication server to specify advanced replication settings like Modifying target table structures, Specifying performance optimization settings Define transformation rules
9.What is Latency?
It is the length of time to replicate data (a table entry) from the source system to the target system.
10.What is logging table?
A table in the source system that records any changes to a table that is being replicated. This ensures that SLT replication server can replicate these changes to the target system.
11.What are Transformation rules?
A rule specified in the Advanced Replication settings transaction for source tables such that data is transformed during the replication process. Example you can specify rule to Convert fields Fill empty fields Skip records
12.What happens when you set-up a new configuration?
The database connection is automatically created along with GUID and Mass transfer id (MT_ID).
A schema GUID ensures that configurations with the same schema name can be created. The Mass transfer ID is used in the naming of SLT jobs and the system can uniquely identify a schema.